Lab 1
- Introduction
- Report
- Reading MNIST Handwritten Digit Dataset
- Some basic operations on tensors
- CIFAR-10 data set
- Useful Resources
Introduction
In this lab, you will learn how to read data from different sources and prepare it for use with pytorch. You will also perform some basic operations on the data you read in order to verify that the conversion worked as intended.
Report
You are required to document your work in a report, that you should write while you work on the lab. Include all requested images, and any other graphs you deem interesting, and describe what you observe. The lab text will prompt you for specific information at times, but you are expected to fill in other text to produce a coherent document. At the end of the lab, send an email with the names and carnés of the students in the group as well as the zip file containing the lab report as a pdf, and all code you wrote to the two professors and the assistant (markus.eger.ucr@gmail.com, joseaguevara@gmail.com, diegomoraj@outlook.com) with the subject “[CI-2600]Lab 1, carné 1, carné 2”. Do not include the data sets in this zip file or email.
Reading MNIST Handwritten Digit Dataset
Your first task is to read the MNIST Handwritten Digit dataset from the binary files provided on the website. Note that the website contains an explanation of the format. Implement a function read_idx that returns an appropriately dimensioned pytorch tensor with the data contained in the file. The header of the file will tell you how many dimensions this tensor should have, as well as the number of entries in each dimension. For example, the image training set will result in a 10000x28x28 tensor, while the training labels will result in a one-dimensional tensor with 10000 entries. The training set corresponds to the 10000 individual images, each of which has a size of 28x28.
Also implement a function save_image that takes a two-dimensional tensor and writes it to a (black-and-white) image using the Python Image Library (PIL). To verify that your loading code works, save several (3-5) images from the training set to files, and include them in your report.
Useful python methods and functions:
-
int.from_bytes(bytes, byteorder="big", signed=True)can be used to convert byte sequencebytes(as read from a file) to an integer -
struct.unpack('f', bytes)can be used to convert a byte sequencebytesto a float value -
PIL.Image.putdatacan be used to assign pixel values to an image (note: it has to be passed a one-dimensional array/list!)
Some basic operations on tensors
Together, the training set images and labels can be used to find only the images that show a particular digit, e.g. 0. For example, the fifth image is shown below, and the fifth entry in the labels array is the integer 4.
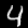
Write a function filter_data that takes a tensor containing images, a tensor containing labels, and a single label, and returns a tensor containing only the images that belong to that class. Then verify that it works by saving a random image from each class.
Next, we want to get a sense of what the “average” digit looks like. Implement a function merge_images that takes a tensor with images and a string, and applies an operation to them which depends on the string, and returns a tensor with a single image as the result. The operations you should support are “max”, “median”, and “mean”. Apply each of these operations to each class of digits individually, i.e. calculate the “average” 0, “average” 1, etc., and the same with the other two operations, and include all 30 images in a table in your report. How do you interpret these images? Do they tell you anything useful about the data?
PyTorch can also execute operations on the GPU. In order to move a tensor from the CPU to the graphics card, you just have to call the cuda method, which will return a reference to a new tensor that is located in GPU memory (only available if the graphics card supports CUDA, which you can check with torch.cuda.is_available). Check if there is a measurable time difference between filtering digits and performing the mean calculation on the CPU vs. on the GPU and report your results.
CIFAR-10 data set
One important consideration for a machine learning system is generalizability. So far, all our operations were done on the MNIST handwritten digits images, which are 28x28 grayscale images. Download the
CIFAR-10 data set and write a function load_cifar that converts them, as well as their class labels into pytorch tensors. Now we have a tensor containing images, and a tensor
containing labels, and should be able to use the same functions as before. Modify the save_image function so that it also support color images, and save one random image from each class. Then apply the mean, max, and median
operations to each class, using your filter_data and merge_images functions. Do the images make sense? If not, what is the problem?