class: center, middle, inverse, title-slide # Jargon, notation, vocabulary (ML vs Stats) ## Best practices for data projects --- 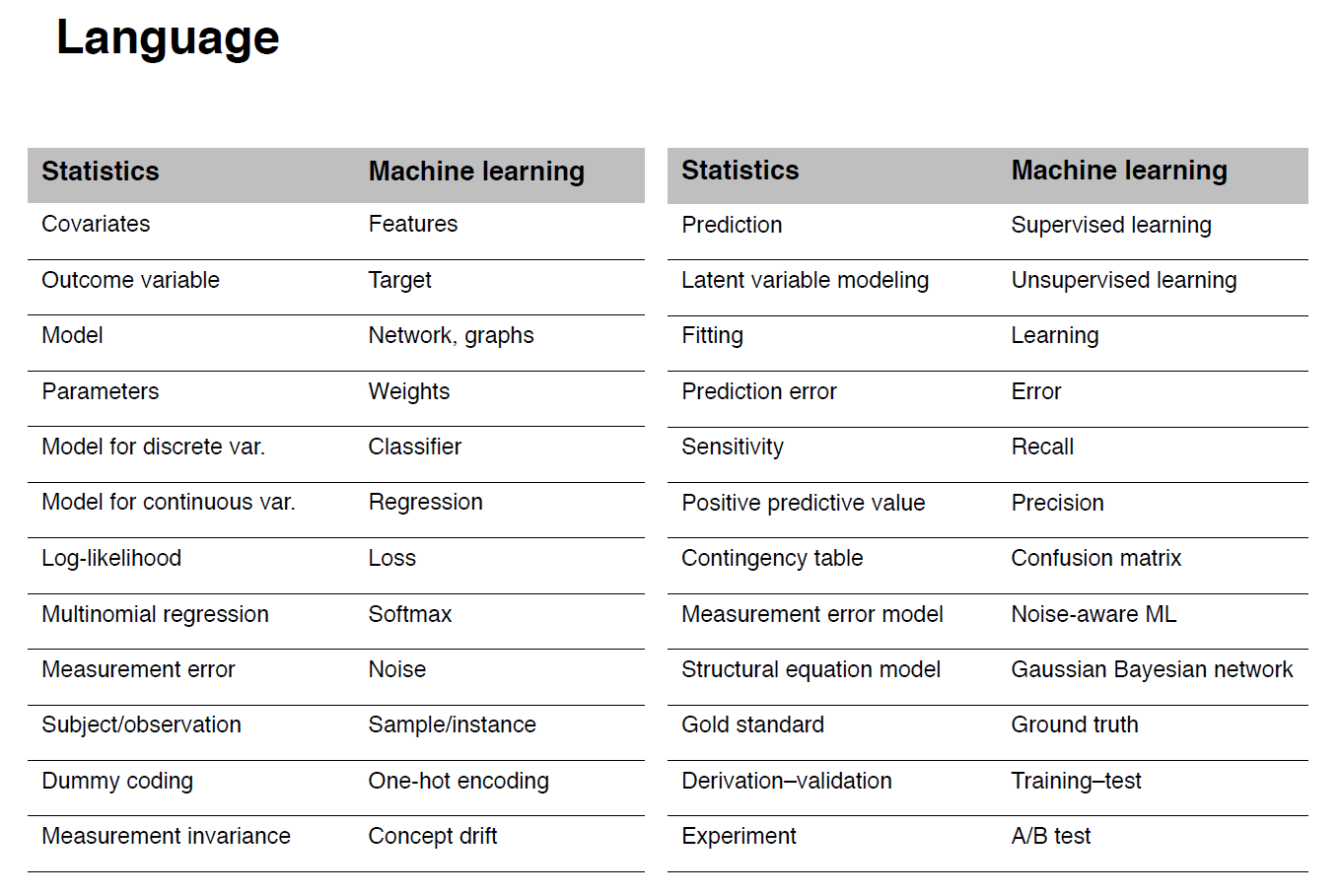 Source: https://twitter.com/MaartenvSmeden/status/1225055692828160002 --- # We are going to discuss today Part I * Covariates vs features * Outcome variable vs target * Model vs network, graphs * Parameters vs weights * Model for discrete variable vs classifier * Model for continuous variable vs regression Part II * Prediction vs supervised learning * Latent variable modeling vs unsupervised learning * Fitting vs Learning * Prediction error vs Error * Contingency table vs Confusion Matrix * Derivation-validation vs Training-test * Experiment vs A/B test --- # Statistics  from: https://link.springer.com/chapter/10.1007%2F978-3-319-46162-5_11 --- # Machine Learning 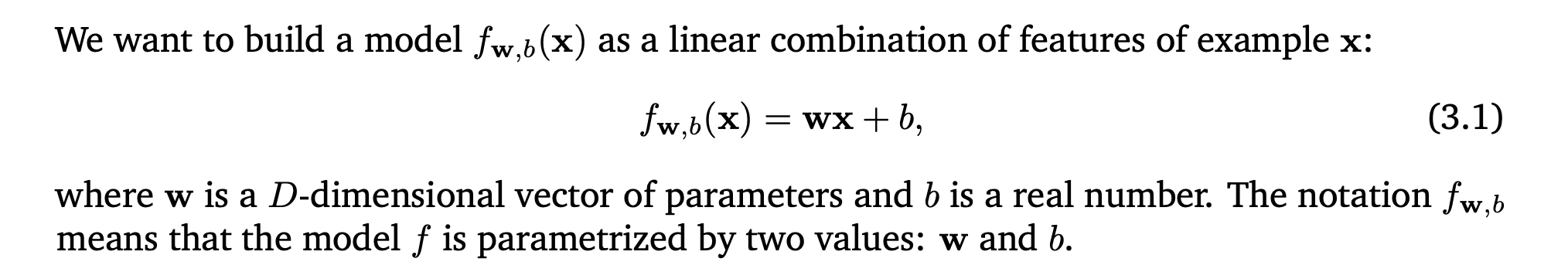 from: The ML book (Burkov 2019) --- # Part II * Prediction vs supervised learning * Latent variable modeling vs unsupervised learning * Fitting vs Learning * Prediction error vs Error * Contingency table vs [Confusion Matrix](https://en.wikipedia.org/wiki/Confusion_matrix) * Derivation-validation vs Training-test * Experiment vs [A/B test](https://en.wikipedia.org/wiki/A/B_testing) --- class: center, middle, reverse # Best practices for data projects --- # Best practices for data projects * Before the project A data management plan is a formal document that outlines: - Research workflow and information about the data that will be generated, collected, or reused. - Research output format, metadata, access and sharing policies, long-term storage, and budget - Creating a data management plan will save you time by creating a clear structure for organizing your data throughout the research life cycle, and ensures that you and others will be able to use and understand your data in the future. See https://dmptool.org/ --- # Best practices for data projects * During the project Set up and document workflows to ensure that data and other research outputs are secure. This includes properly backing up, protecting, and archiving data and code. - Start by following the 3-2-1 rule: store three copies of data and code at two different locations with one copy in the cloud (or offsite) - Some research data may also fall under restricted or confidential categories, and it is critical that proper policy compliance is both taken and recorded. - Code must be commented and well docummented, think about the future you reading it, after having left the project for a year or two. --- # Best practices for data projects * After the project Upon completion of a project, select an archival data repository to publish your research data outputs. Repositories ensure that your data will be stored and can be accessed for future use, either by you or other researchers. Publishers and funding institutions have guidelines to address data access and archiving through using trusted data repositories that ensure long term archiving and discoverability. By properly archiving data and other outputs, research is more likely to be cited, reused, and discovered in search engines. See https://www.go-fair.org/fair-principles/ --- # Reproducibility ## Why? - to show evidence of the correctness of your results. - to enable others to make use of our methods and results. "An article about computational results is advertising, not scholarship. The actual scholarship is the full software environment, code and data, that produced the result" (Claerbout and Karrenbach, 1992). https://ropensci.github.io/reproducibility-guide/sections/introduction/ --- # Reproducibility ## What? (Stodden (2014)) * Computational reproducibility: when detailed information is provided about code, software, hardware and implementation details. * Empirical reproducibility: when detailed information is provided about non-computational empirical scientific experiments and observations. In practise this is enabled by making data freely available, as well as details of how the data was collected. * Statistical reproducibility: when detailed information is provided about the choice of statistical tests, model parameters, threshold values, etc. This mostly relates to pre-registration of study design to prevent p-value hacking and other manipulations. --- # Computational reproducibility: * Reviewable Research. The descriptions of the research methods can be independently assessed and the results judged credible. * Replicable Research. Tools are made available that would allow one to duplicate the results of the research. * Confirmable Research. The main conclusions of the research can be attained independently without the use of software provided by the author. * Auditable Research. Sufficient records (including data and software) have been archived so that the research can be defended later if necessary or differences between independent confirmations resolved. * Open or Reproducible Research. Auditable research made openly available. This comprised well-documented and fully open code and data that are publicly available that would allow one to (a) fully audit the computational procedure, (b) replicate and also independently reproduce the results of the research, and (c) extend the results or apply the method to new problems. --- # Reproducibility ## How? (Stodden et al (2013)) - Literate computing, authoring, and publishing. These tools enable writing and publishing self-contained documents that include narrative and code used to generate both text and graphical results. - Version control. These tools enable you to keep a record of file changes over time, so specific versions can be recalled later. - Tracking provenance. Provenance refers to the tracking of chronology and origin of research objects, such as data, source code, figures, and results. --- # Reproducibility ## How? (Stodden et al (2013)) - Automation. Several Unix tools are useful for streamlined automation and documentation of the research process, e.g. editing files, moving input and output between different parts of your workflow, and compiling documents for publication. - Capturing the computational environment. A substantial challenge in reproducing analyses is installing and configuring the web of dependencies of specific versions of various analytical tools. More tools: http://ropensci.github.io/reproducibility-guide/ --- # Reproducibility ## For your labs and projects - Can you use some of these recomendations? - Which ones are you using now? - Which ones would you like to use? --- class: center, middle, reverse Slides creadas via R package [**xaringan**](https://github.com/yihui/xaringan). El chakra viene de [remark.js](https://remarkjs.com), [**knitr**](http://yihui.name/knitr), and [R Markdown](https://rmarkdown.rstudio.com).